

Gemini query parametrelerini desteklemediği için prompt metni panonuza kopyalandı. Gemini sayfasında yapıştırabilirsiniz.
Bir web sitesinde “yayınladım, linkledim, sitemap’e ekledim… ama sayfa aramalarda yok” durumu, çoğu zaman teknik bir hata gibi görünür. Oysa sahada en sık karşılaştığım gerçek şu: Google, her erişilebilir URL’yi dizine almak zorunda değildir; hatta sistemin sağlıklı çalışması için bazı URL’leri bilinçli biçimde dışarıda bırakır.
Yanlış beklenti genelde tek noktada toplanır: “Index = otomatik ve garanti.” Google’ın dokümantasyonu, tarama–işleme–serve (sonuçlarda gösterme) akışının üç ayrı aşama olduğunu; her sayfanın her aşamadan geçmeyebileceğini ve hiçbir aşama için garanti bulunmadığını açık şekilde söyler.
Benim yaklaşımım şudur: “Indexlenmiyor” cümlesini bir sorun etiketi gibi değil, bir teşhis başlangıcı gibi ele almak gerekir. Bazı URL’ler teknik olarak indexlenebilir olsa bile, dizin kalitesi, yinelenen içerik kümeleri, aşırı URL üretimi, düşük değer sinyalleri, erişim kısıtları veya yönlendirme/kanonik tercihleri yüzünden dışarıda kalabilir.
Google’ın Indexleme Kararını Anlamadan Sorun Çözülmez…
İndexlenmeme durumu çoğu zaman “Google sayfayı sevmedi” gibi yorumlanıyor. Gerçekte Google; kaynak yönetimi, dizin kalitesi ve kullanıcıya doğru sürümü gösterme hedefiyle hareket eder. Tarama kapasitesi sınırlıdır, tarama talebi değişkendir ve her URL’nin aynı önceliği yoktur.
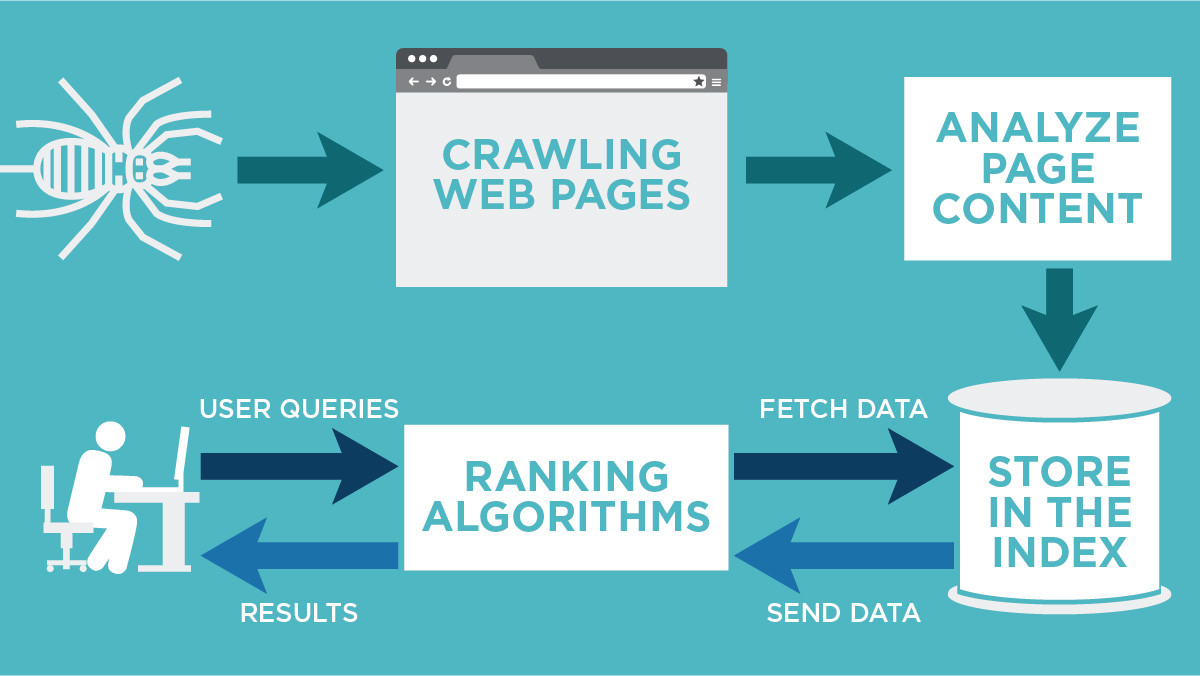
Google’ın resmi “How Search works” dokümanı üç aşamayı netleştirir: keşfetme/tarama, indexleme, sonuçlarda gösterme.
Önemli detay: Sayfa Search Essentials’a uyuyor olsa bile Google; tarama, indexleme veya sonuçlarda gösterme sözü vermez.
Sahada yanlış takılan ikinci konu “URL sayısı = fırsat” varsayımıdır. Search Console yardım dokümanı, %100 kapsama beklememeniz gerektiğini; genelde yalnızca kanonik sayfaların indexlenmesini hedeflemenin doğru olduğunu özellikle vurgular.
Google’ın Bilerek Indexlemediği URL Türleri Nelerdir?
Google’ın “bilerek indexlememe” davranışı, genelde tek bir sebebe dayanmaz; bir URL’nin dizine girmesi için çoklu sinyallerin aynı yönde tutarlı olması gerekir. Eğer sinyaller “gerekli değil”, “tekrarlı”, “erişilemez”, “değer düşük”, “riskli” veya “yanlış sürüm” yönünde birleşiyorsa, dışarıda kalması sistem açısından normaldir.
Aşağıdaki başlıklar, en sık gördüğüm “kasıtlı dışlama” kümeleridir.
Yönlendiren URL’ler ve Kanonik Olmayan Kopyalar
Yönlendirme yapan bir URL’nin kendisi genellikle indexlenmez; hedef URL temsilî kabul edilir. Search Console, “Page with redirect” gibi durumları doğrudan “indexlenmeyecek normal davranış” olarak tanımlar.
Benzer şekilde, aynı içeriğin farklı URL’lerde erişilebilir olması halinde Google, arama sonuçlarında tek bir sürümü göstermek için kanonik seçimi yapar. Search Console yardım sayfası, filtre/sıralama gibi varyasyonların “indexlenmesi uygun olmayan” URL örnekleri olduğunu açıkça söyler.
Parametreli/Filtreli URL Uzayları ve “Sonsuz Varyasyon” Riski
Filtreleme ve fasetli gezinme, kullanıcı deneyimi açısından değerli olabilir; fakat URL parametreleri kontrolsüz bırakıldığında aşırı URL üretir. Google’ın fasetli gezinme rehberinde, bu tarz URL’lerin büyük URL uzayları üretebileceği ve tarama maliyetini arttırabileceği vurgulanır.
Search Console yardım dokümanı da benzer şekilde, renk–beden–sıralama gibi parametre varyasyonlarının “duplicate/alternate” kümelerine dönüşerek index dışına çıkmasının çok yaygın olduğunu belirtir.
Robots.txt Engeli veya noindex Direktifi
Bazı URL’lerin indexlenmemesi tamamen “site sahibinin kararıdır”: robots.txt ile taramanın engellenmesi veya sayfaya noindex direktifi verilmesi gibi. Search Console, “URL blocked by robots.txt” ve “URL marked ‘noindex’” nedenlerini doğrudan listeler.
Burada kritik ayrım: robots.txt taramayı sınırlar; indexlemeyi her zaman kesin biçimde durdurmayabilir. Search Console dokümanı, robots.txt ile engellenmiş bir URL’nin çok küçük bir olasılıkla yine de indexe girebileceğini ve snippet’in sınırlı kalacağını anlatır.
Ayrıca noindex’in işe yaraması için sayfanın taranabilir olması gerekir; noindex’i robots.txt ile kapatılmış bir sayfaya eklemek, pratikte “Google noindex’i göremesin” anlamına gelebilir. Google’ın noindex dokümanı bu şartı özellikle vurgular.
Erişim Kısıtları, Yetkilendirme ve Hata Yanıtları
Googlebot kimlik bilgisi sağlamaz. Search Console, 401 (yetkilendirme), 403 (erişim yasak) gibi durumlarda sayfanın indexlenmeyeceğini net biçimde açıklar.
Sunucu hataları (5xx) de benzer şekilde taramayı yavaşlatır; içerik işlenmez ve kalıcılaşırsa zaman içinde dizinden düşme riski artar. Google’ın HTTP durum kodları dokümanı, 5xx ve 429 gibi hataların taramayı geçici olarak yavaşlattığını ve 5xx dönen URL’lerden alınan içeriğin yok sayıldığını belirtir.
Soft 404 ve “Var Gibi Görünen Yok Sayfalar”
Soft 404, teknik olarak 200 dönen ama içerik olarak “yok / bulunamadı / boş” görünen sayfalardır. Search Console, “Submitted URL seems to be a Soft 404” yaklaşımını ve nedenini açıklar.
Google’ın eski ama hâlâ referans niteliğindeki blog yazısı, soft 404’lerin kullanıcı ve arama sistemleri için kafa karıştırıcı olduğunu; gerçek “bulunamadı” durumlarında 404 döndürmenin daha sağlıklı olduğunu anlatır.
Spam Politikalarıyla Çelişen Sayfalar ve Riskli İçerik Desenleri
“Indexlenmiyor” her zaman teknik bir mesele değildir. Google Search Essentials içindeki spam politikaları; sayfa veya sitenin, spam davranışlarıyla ilişkilendirilmesi halinde daha düşük sıralama veya tamamen kaldırılma (omitted) gibi sonuçlara yol açabileceğini söyler.
Kastedilen; arama sonuçlarını manipüle etmeye dönük, kullanıcıyı kandıran veya düşük değer üreten ölçekli sayfa desenleridir. Google’ın spam politikaları bu tür davranışları ve sonuçlarını açık çerçevede tarif eder.
Search Console’da “Neden Indexlenmedi” Bilgisini Doğru Okumak
Search Console raporları tek başına hüküm vermez; fakat doğru okunduğunda kararın “kasıtlı mı, geçici mi, site kaynaklı mı” olduğunu hızlıca ayırt ettirir. “Page indexing report” dokümanı, “Not indexed” durumunun bazen hata, bazen de meşru dışlama nedeni olabileceğini ve sebeplerin raporda listelendiğini söyler.
Benim sahadaki rutinim, raporları şu mantıkla katmanlara ayırmaktır:
- Engellenmiş mi? (robots/noindex/401/403)
- Kopya kümesi mi? (alternate/duplicate/kanonik seçimi)
- Keşif ve tarama gecikmesi mi? (discovered/crawled currently not indexed)
- Kalite–değer sinyali mi? (crawled—currently not indexed, ama teknik engel yok)
“Crawled — currently not indexed” Ne Demek?
Search Console, bu durum için “sayfa tarandı ama indexlenmedi; gelecekte indexlenebilir ya da indexlenmeyebilir; tekrar göndermeye gerek yok” ifadesini kullanır. Yani bir hata kodu değil; bir karar/erteleme bildirimi gibi düşünmek daha doğru olur.
Buradaki temel soru: Google sayfayı gördü, taradı; fakat “dizine değer” sinyali yeterli değil mi, yoksa sayfa başka bir URL’ye kanonik olarak bağlanmalı mı? Çözüm yolu, rapordaki diğer sinyallerle birlikte değerlendirilir.
“Discovered — currently not indexed” Ne Demek?
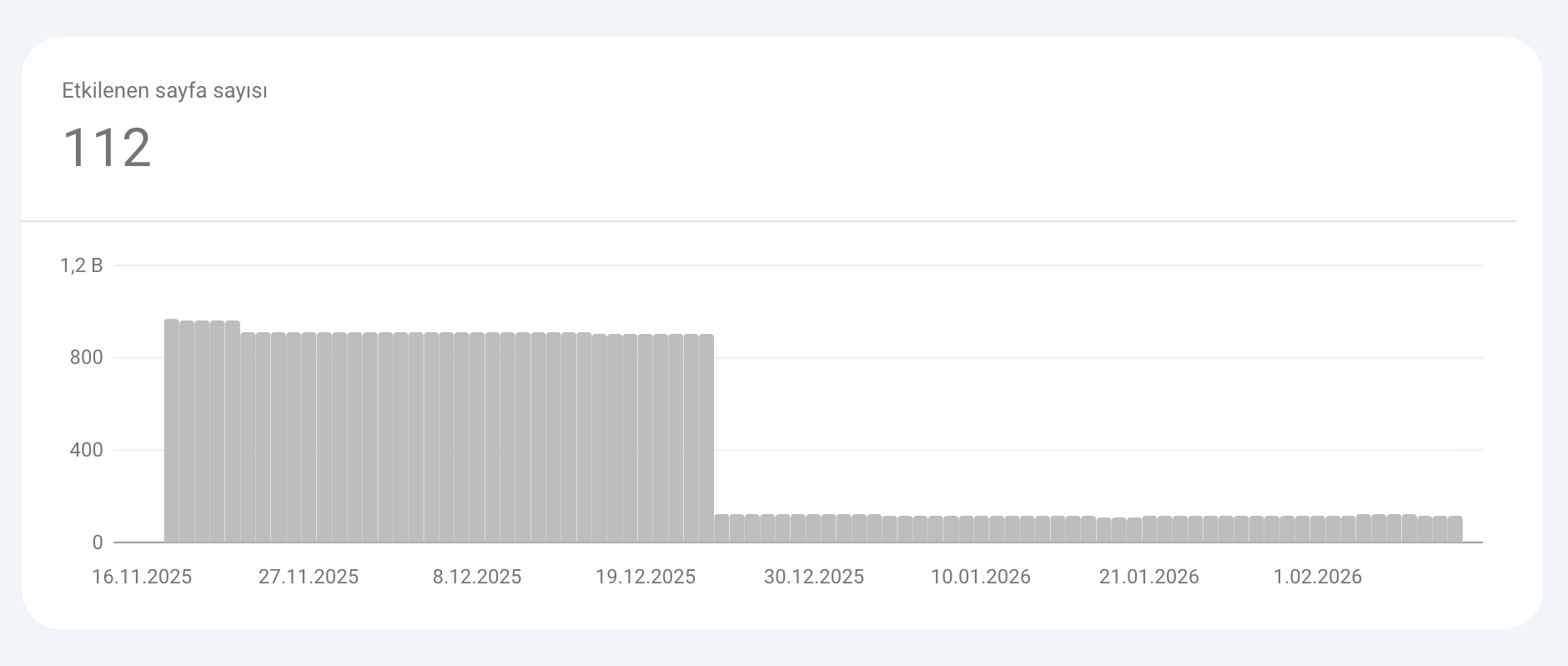
Search Console, bu durumu çoğunlukla “Google URL’yi keşfetti, taramak istedi ama siteyi zorlamamak için erteledi; bu yüzden son tarama tarihi boş” şeklinde açıklar. Pratik karşılığı: URL biliniyor; tarama önceliği veya kapasitesi nedeniyle sıra gelmiyor.
Bu durumun sık görüldüğü senaryolar: gereksiz URL üretimi, ağır sayfalar, zayıf iç link ağı, düşük tarama talebi veya sunucu tarafında yanıt/kapasite sorunları. Crawl budget dokümanı; tarama bütçesinin “tarama kapasitesi limiti + tarama talebi” ile belirlendiğini ve gereksiz URL’lerin bu dengeyi bozabileceğini anlatır.
Kanonik Seçimiyle İlgili Durumlar Neden Kritik?
Search Console; “Duplicate, Google chose different canonical than user”, “Alternate page with proper canonical tag”, “Duplicate without user-selected canonical” gibi satırlarla aslında tek cümle kurar: “Benzer sayfalar arasında temsilî bir URL seçtim.”
Google’ın kanonik sorun giderme dokümanı, sizin belirlediğiniz kanoniğe rağmen Google’ın başka bir URL seçebileceğini; bunun nedenlerinden birinin içerik kalitesi/sinyal uyumsuzluğu olabileceğini söyler.
Indexlenmeyen URL’lerle uğraşırken en çok zaman kaybettiren şey, her URL’ye “tekil vaka” muamelesi yapmaktır. Verimli yöntem, önce sınıflandırmak; sonra kök nedeni birkaç kontrolle ortaya çıkarmaktır.
Benim kullandığım akış, Search Console’un resmi rapor mantığıyla birebir uyumludur: önce engeller, sonra kanonik/duplikasyon, sonra keşif–tarama gecikmesi, en son değer sinyali.
Aşağıdaki sıra, çoğu projede 30–60 dakika içinde netlik sağlar.
Sayfa Google Tarafından Gerçekten Görülebiliyor mu?
İlk adım “tarama izni” ve “erişilebilirlik”. robots.txt, noindex, yetkilendirme veya 4xx/5xx hata kodları varsa index konuşmak erkendir. Search Console, URL Inspection aracını kullanarak tekil bir URL’nin neden indexlenmediğini görmeyi önerir.
Robots tarafında iki kaynak birlikte okunmalı: Google’ın robots.txt yorumlama sayfası ve robots standardı. Google, robots.txt’yi taramadan önce indirip parse ettiğini belirtir; ayrıca status kodlarına göre robots.txt’nin nasıl ele alındığını (4xx → kısıt yok varsayımı gibi) açıklar.
Noindex Etiketi İstemeden mi Aktif?
Noindex, “kasıtlı dışlama” kategorisinin en net örneğidir. Google’ın dokümanı, noindex’in meta etiket veya HTTP başlığıyla uygulanabileceğini; Googlebot sayfayı tarayıp noindex’i gördüğünde sayfayı sonuçlardan düşürdüğünü açıklar.
En sık rastladığım hata: sayfa noindex’li kalır, sonra “index isteği” atılır. Google, noindex bulunan sayfayı indexlemeyeceği için talep boşa gider; önce noindex kaldırılır, sonra yeniden tarama tetiklenir.
Kanonik Sinyaller Aynı Şeyi mi Söylüyor?
Kanonik konusu, “neden bazı URL’ler bilerek indexlenmez” sorusunun merkezinde durur; çünkü Google çoğu zaman aynı içeriğin tek sürümünü indexlemek ister. Search Console raporundaki duplicate/alternate durumları, sistemin normal davranışıdır.
Kanonik sorun giderme sayfası, URL Inspection ile Google’ın seçtiği kanoniği kontrol etmeyi önerir; ayrıca Google’ın sizin seçiminizden farklı bir kanonik seçebileceğini (ör. kalite, sinyal tutarsızlığı, sunucu yanlış yapılandırması, kötü niyetli müdahale vb.) belirtir.
Benim pratik kontrolüm üçlüdür:
- Sayfanın bölümünde rel=canonical nereye gidiyor?
- Site içi linkler hangi sürüme yoğunlaşıyor?
- Sitemap hangi URL’yi “kanonik” olarak öneriyor?
Sitemap rehberi, sitemap’e kanonik URL’leri koymanız gerektiğini açıkça söyler; sitemap bir ipucudur, garanti değildir ama sinyal tutarlılığında kritiktir.
Parametre, Filtre ve Sayfalama URL’leri Gerçekten Gerekli mi?
Search Console yardım dokümanı, filtre varyasyonlarının indexlenmesinin uygun olmadığını doğrudan örnekler.
Google’ın fasetli gezinme rehberi ise iki senaryo sunar:
- Indexlenmesi gerekmeyen faceted URL’ler için taramayı engelleyin.
- Indexlenmesi istenen faceted URL’ler için best practice’e göre yönetin (ama bunun maliyetini bilin).
Benim danışmanlık bakışımda, faceted URL’lerin indexlenmesi ancak “gerçek arama talebi + benzersiz içerik + stabil URL + net kanonik strateji” varsa anlam kazanır. Aksi halde dizine şişkinlik ve tarama kaybı üretir.
Sunucu Yanıtı ve Yönlendirme Hijyeni Kontrolü
Google’ın “Redirects and Google Search” dokümanı, yönlendirmelerin kanonik sinyali olarak güçlü/zayıf şekilde yorumlanabildiğini ve hangi durumda hangi redirect’in daha uygun olacağını anlatır.
Google’ın HTTP status codes rehberi, özellikle 5xx ve 429’un taramayı yavaşlattığını; 5xx dönen URL içeriğinin yok sayıldığını belirtiyor. Eğer “discovered”/“crawled not indexed” artıyorsa altyapı sağlığı da mutlaka masaya konmalı.
Pro Tip: Index sorunlarında “tek tek URL gönderme” refleksi, kısa vadeli rahatlatır ama kalıcı çözüm üretmez. Benim sağlam sonuç aldığım yöntem: önce URL setini daraltıp netleştirmek, sonra Google’a “öncelikli sayfalar bunlar” mesajını site içi sinyallerle vermek. Sitemap’te yalnız kanonik URL’ler, güçlü iç link yapısı ve gereksiz parametre uzayının kontrolü bir araya geldiğinde “discovered” birikimi çoğu projede dramatik şekilde azalır.
Kalıcı Çözüm Stratejisi
Kalıcı başarı için hedef, “tüm URL’leri indexletmek” değil; arama niyetiyle eşleşen, tekil değer üreten ve temsilî olarak seçilmesi mantıklı sayfalar üretmektir. Google’ın Search Console dokümanı, tüm URL’lerin indexlenmesini beklememeniz gerektiğini özellikle söyler; kanonik sayfalar asıl hedeftir.
Stratejiyi üç katmanda kurmak gerekir.
Dizin Kalitesi ve Site İçi Sinyal Tutarlılığı
Google, duplicate sayfaları indexlememe eğilimindedir; bunun yerine bir sürüm seçer. Sinyaller tutarsızsa seçilen sürüm “ekibin hedeflediği URL” olmayabilir. Kanonik sorun giderme dokümanı, Google’ın farklı kanonik seçebileceğini ve önce Google seçiminin kullanıcılar açısından daha mantıklı olup olmadığını düşünmeyi önerir.
Benim sahada gördüğüm en etkili iyileştirme: her içerik kümesi için “tek temsilî URL” politikasını içerik üretim sürecine gömmek. İç linkler, sitemap, redirect kararları ve canonical etiketleri aynı şeyi söylemeye başladığında, Google’ın karar vermesi kolaylaşır.
Tarama Bütçesi Mantığıyla Gereksiz URL Üretimini Azaltmak
Google’ın crawl budget rehberi, crawl budget’in “Google’ın tarayabildiği ve taramak istediği URL seti” olduğunu söyler; gereksiz URL’lere ayrılan kaynak, değerli URL’lere gitmez.
Fasetli gezinme rehberi, faceted URL’lerin tarama maliyetinin yüksek olabileceğini net biçimde belirtir. Bu yüzden, her parametreli URL’nin “crawl edilebilir bir sayfa” olarak doğması, çoğu sitede indexleme gecikmesini tetikler.
Spam Politikalarına Takılabilecek Sayfa Desenlerinden Kaçınmak
Google’ın spam politikaları, spam davranışların sayfaların daha düşük sıralanmasına veya tamamen kaldırılmasına yol açabileceğini söyler. Buradaki risk, tek bir sayfanın değil; site genelindeki desenlerin güven sinyalini düşürmesidir.
Kısacası: teknik olarak taranan bir sayfa, spam politikalarına yakın bir desen taşıyorsa veya “düşük değerli ölçekli sayfa üretimi” izlenimi veriyorsa, index kapısı daralır.
Benim Yaklaşımım: “Crawled — currently not indexed” vakalarında en hızlı içgörü, URL Inspection’ın verdiği Google-seçimli kanonik bilgisini, sayfanın site içi link aldığı sürümle karşılaştırmaktan gelir. Eğer site içi link akışı bir varyasyonu “asıl sayfa” gibi besliyorsa, canonical etiketi tek başına yeterli olmaz; iç link mimarisi düzeltilmeden index davranışı kalıcı şekilde değişmeyebilir.
Sık Sorulan Sorular
Yayında “indexlenmiyor” sorusu genelde aynı alt sorulara ayrılıyor. Aşağıdaki cevaplar, Search Console ve Google dokümanlarının çizdiği çerçeveyle uyumlu olacak şekilde pratikte netlik sağlar.
Sitemap’e Eklediğim Her URL Indexlenmek Zorunda mı?
Hayır. Google sitemap’i bir ipucu olarak görür, garanti olarak değil. Ayrıca sitemap’e kanonik URL’lerin konması önerilir; aynı içeriğin farklı sürümlerini sitemap’e doldurmak, sinyal tutarlılığını bozabilir.
“Discovered — currently not indexed” Görünce Hemen mi Paniklemeliyim?
Panik yerine sınıflandırma daha doğru. Search Console, tipik sebebin siteyi aşırı yüklememek için taramanın ertelenmesi olduğunu söyler. Süre uzuyorsa, tarama bütçesi, sunucu kapasitesi, URL üretimi ve iç link sinyallerine bakmak gerekir.
Robots.txt ile Kapattığım Sayfa Yine de Aramada Görünebilir mi?
Çok düşük bir ihtimalle evet. Search Console dokümanı, robots.txt engelinin taramayı durdurduğunu ama başka sinyallerle URL’nin indexe girebileceğini; snippet’in kısıtlı kalabileceğini belirtir. Index dışında tutmak için noindex gibi yöntemler gerekir (sayfa taranabilir olmalı).
Noindex Ekledim ama Sayfa Hâlâ Aramada Çıkıyor; Neden?
Google’ın noindex dokümanı, noindex’i görebilmesi için önce sayfayı taraması gerektiğini anlatır; ayrıca robots.txt engeli varsa noindex görünmeyebilir. Bir diğer neden, Google’ın henüz yeniden taramamış olmasıdır; URL Inspection ile yeniden tarama talebi tetiklenebilir.
Kanonik Etiketi Koydum; Google Neden Başka URL’yi Seçiyor?
Google’ın kanonik sorun giderme sayfası, sizin belirlediğiniz kanoniğe rağmen Google’ın farklı bir kanonik seçebileceğini söyler. En yaygın sebepler: sinyal tutarsızlığı (iç link, redirect, sitemap, hreflang vb.) veya sayfalar arası kalite/benzerlik farklarının Google’ın gözünde sizden farklı görünmesi.
Soft 404 Tam Olarak Neyi İfade Ediyor?
Genelde “sayfa yok” davranışı gösteren ama 200 dönen sayfaları ifade eder. Google, soft 404 kullanımını önermediğini ve gerçek “yok” durumlarında 404 döndürmenin daha doğru olduğunu anlatır. Search Console da soft 404’ü raporlar ve canlı testle Google’ın gördüğü ekran görüntüsünü kontrol etmeyi önerir.
Kapanış
Özetle, Google’ın bazı URL’leri bilerek indexlememesi “engel” değil; çoğu zaman normal bir kalite ve kaynak yönetimi davranışıdır. Sağlıklı yaklaşım; hedef URL setini netleştirmek, sinyalleri tutarlı hale getirmek ve gereksiz URL üretimini kontrol altına almaktır. Search Console dokümanlarının ortak mesajı da aynıdır: Her URL değil, doğru kanonik sayfalar hedeflenmelidir.

Ahmet Abiç, SEO uzmanı ve dijital strateji danışmanıdır. Teknik SEO, içerik stratejisi ve veri odaklı büyüme modelleri üzerine çalışır. Türkiye ve uluslararası projelerde markaların organik görünürlüğünü artırmaya yardımcı olur ve SEO'yu sadece sıralama değil sürdürülebilir dijital büyüme aracı olarak görür.
Paylaşarak başkalarının da faydalanmasına yardımcı olun.